
Boosting and Bagging in Machine Learning
Ensemble techniques to improve performance of machine learning models.

Introduction
Machine learning and data science models need to be continuously improved as the input data to the model changes, models may become suboptimal. Two powerful ensemble learning techniques, boosting and bagging, have emerged as effective methods for achieving this. These techniques combine multiple models to produce a more accurate and stable prediction than any individual model could. This article explores what boosting and bagging are, how they work, and provides examples from various domains to illustrate their application.
What are Boosting and Bagging?
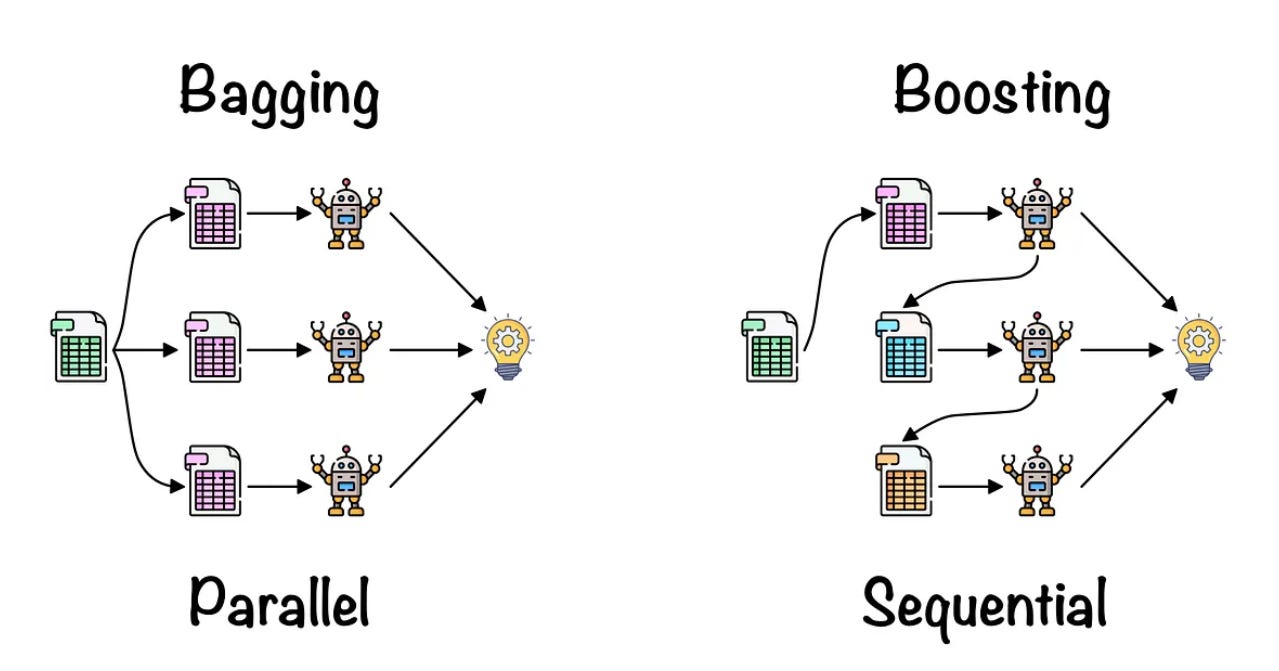
Bagging (Bootstrap Aggregating) is designed to reduce the variance of a model by training multiple models on different subsets of the training data and then averaging their predictions. This technique is particularly useful when dealing with high-variance models, such as decision trees.
Boosting aims to reduce both bias and variance by sequentially training models. Each model in the sequence focuses on correcting the errors made by the previous models. Common boosting algorithms include AdaBoost, Gradient Boosting, and XGBoost.
Figure - Illustrating Bagging vs Boosting
Credits: Flaticon.com
Key Parameters in Bagging and Boosting
Both bagging and boosting involve several parameters that control their behavior:
base_estimator: The base model used to create multiple instances (e.g.,DecisionTreeClassifierorDecisionTreeRegressor).n_estimators: The number of base models or boosting stages to be trained. Increasing this number generally improves performance but also increases computational cost.random_state: A seed for the random number generator to ensure reproducibility of results.
Bagging Examples
1. Finance: Predicting Stock Prices
Bagging can be used to predict stock prices by aggregating predictions from multiple models trained on different subsets of historical stock data.
from sklearn.ensemble import BaggingRegressor
from sklearn.tree import DecisionTreeRegressor
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Assume we have a DataFrame df with stock features and target price
# df = pd.read_csv('stock_data.csv')
X = df.drop('price', axis=1)
y = df['price']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
base_model = DecisionTreeRegressor()
bagging_model = BaggingRegressor(base_estimator=base_model, n_estimators=50, random_state=42)
bagging_model.fit(X_train, y_train)
y_pred = bagging_model.predict(X_test)
print(f'Mean Squared Error: {mean_squared_error(y_test, y_pred)}')2. Healthcare: Disease Diagnosis
Bagging can improve the accuracy of disease diagnosis by aggregating predictions from multiple models trained on different subsets of patient data.
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load dataset
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
base_model = DecisionTreeClassifier()
bagging_model = BaggingClassifier(base_estimator=base_model, n_estimators=50, random_state=42)
bagging_model.fit(X_train, y_train)
y_pred = bagging_model.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')Boosting Examples
1. Marketing: Customer Churn Prediction
Boosting can predict customer churn by sequentially training models to focus on customers most likely to churn based on historical data.
from sklearn.ensemble import GradientBoostingClassifier
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Assume we have a DataFrame df with customer features and churn target
df = pd.read_csv('customer_churn.csv')
X = df.drop('churn', axis=1)
y = df['churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
boosting_model = GradientBoostingClassifier(n_estimators=100, random_state=42)
boosting_model.fit(X_train, y_train)
y_pred = boosting_model.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')2. E-commerce: Product Recommendation
Boosting can improve the accuracy of product recommendations by focusing on patterns in customer behavior that previous models missed.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Assume we have a DataFrame df with user features and product purchase target
# df = pd.read_csv('product_recommendation.csv')
X = df.drop('purchased', axis=1)
y = df['purchased']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
base_model = DecisionTreeClassifier()
boosting_model = AdaBoostClassifier(base_estimator=base_model, n_estimators=100, random_state=42)
boosting_model.fit(X_train, y_train)
y_pred = boosting_model.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')Summary
Boosting and bagging are powerful techniques in the data scientist’s toolkit, capable of enhancing model performance across various domains. By understanding and leveraging these methods, one can build more accurate and robust models, whether predicting stock prices, diagnosing diseases, forecasting customer churn, or recommending products. These techniques demonstrate the power of ensemble learning in tackling complex predictive tasks.