
Creating a Retrieval Augmented Generation (RAG) App with LangChain, Promptflow and Semantic Kernel
Comparing the most popular RAG tools.

Introduction
Creating simple Retrieval-Augmented Generation (RAG) chatbots using LangChain, Promptflow, and Semantic Kernel involves different approaches and tools. Here's a comparison and overview of how to create RAG chatbots with each framework.
LangChain
LangChain is a framework that helps build applications with large language models. It provides tools to manage prompts, chain LLMs together, and integrate with external data sources for retrieval.
Figure - LangChain Overview
Steps to Create a RAG Chatbot with LangChain:
Setup Environment: Install the necessary libraries
pip install langchain openai faissInitialize LangChain Components:
Define a retriever using FAISS (or another vector store).
Create a language model instance (e.g., OpenAI's GPT-3).
Chain them together.
Example Code:
from langchain import OpenAI, VectorDBQA from langchain.vectorstores import FAISS from langchain.embeddings.openai import OpenAIEmbeddings # Initialize the retriever embeddings = OpenAIEmbeddings() vector_store = FAISS.from_documents(documents, embeddings) retriever = VectorDBQA(vector_store) # Initialize the language model llm = OpenAI(api_key="your_openai_api_key") # Create the chain chain = retriever | llm # Define a query query = "What is the capital of France?" # Get the response response = chain.run(query) print(response)
Promptflow
Promptflow is a platform for managing, deploying, and iterating on LLM prompts. It allows for easy integration with various models and APIs.
Figure - Promptflow Overview
Steps to Create a RAG Chatbot with Promptflow:
Setup Environment: Install Promptflow SDK.
pip install promptflowDefine Prompts and Workflows:
Create a retrieval component.
Define the generation prompt.
Set up the workflow to chain them together.
Example Code:
import requests
import promptflow as pf
from promptflow.components import OpenAI, VectorSearch
from promptflow.text_splitter import RecursiveCharacterTextSplitter
# Fetch the document content from the URL
url = "https://example.com/document"
response = requests.get(url)
document_text = response.text
# Split the document text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_text(document_text)
# Initialize vector search with chunks
vector_search = VectorSearch.from_texts(chunks, model_name="openai_embedding_model")
# Initialize text generator
generator = OpenAI(api_key="your_openai_api_key")
# Define workflow
workflow = pf.Workflow(
steps=[
vector_search,
generator
]
)
# Define a query
query = "What is the capital of France?"
# Run the workflow
response = workflow.run(query)
print(response)
Semantic Kernel
Semantic Kernel is a lightweight framework designed to handle semantic search and text generation. It emphasizes modularity and ease of use.
Figure - Semantic Kernel
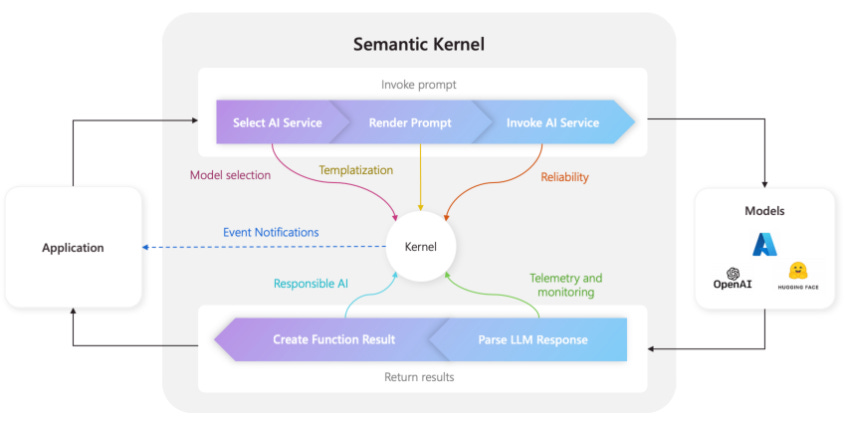
Steps to Create a RAG Chatbot with Semantic Kernel:
Setup Environment: Install Semantic Kernel.
pip install semantic-kernelInitialize Semantic Kernel Components:
Set up a semantic search engine.
Integrate with a text generation model.
Example Code:
import requests from semantic_kernel import SemanticKernel, SearchEngine, TextGenerator from semantic_kernel.text_splitter import RecursiveCharacterTextSplitter # Fetch the document content from the URL url = "https://example.com/document" response = requests.get(url) document_text = response.text # Split the document text into chunks text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) chunks = text_splitter.split_text(document_text) # Initialize search engine with chunks search_engine = SearchEngine.from_texts(chunks, model_name="openai_embedding_model") # Initialize text generator text_generator = TextGenerator(api_key="your_api_key") # Create semantic kernel kernel = SemanticKernel(search_engine, text_generator) # Define a query query = "What is the capital of France?" # Get the response response = kernel.query(query) print(response)
Comparison
LangChain:
Strengths: Highly modular, easy to integrate with various LLMs and vector stores, extensive chaining capabilities.
Use Cases: Complex applications requiring multiple LLMs, custom chains, and flexible integrations.
Promptflow:
Strengths: Simplified prompt management, easy iteration on prompts, integrated workflow management.
Use Cases: Applications needing rapid prototyping and iteration on prompts, deployment of prompt workflows.
Semantic Kernel:
Strengths: Lightweight, focused on semantic search and generation, easy to set up.
Use Cases: Simple applications needing semantic search and text generation without extensive customization.
Summary
Each framework has its strengths and is suited to different types of RAG chatbot applications. LangChain offers the most flexibility and power for complex integrations, Promptflow excels in prompt management and workflow iteration, and Semantic Kernel provides a straightforward approach for simpler use cases. Choose the one that best fits the complexity and requirements of your project.